



El stack y el heap (Breve repaso)
Es importante recordar que en muchos lenguajes de programación, no es necesario prestar mucha atención a la distinción entre la stack y el heap. Sin embargo, en un lenguaje de programación de sistemas como Rust, la ubicación de un valor en la stack o en el heap afecta el comportamiento del lenguaje y determina las decisiones que debe tomar como desarrollador.
Tanto el stack como el heap son regiones de memoria disponibles para el uso del código durante la ejecución, pero están estructuradas de manera diferente. El stack almacena valores en el orden en que son recibidos y los elimina en orden inverso, siguiendo el principio de "último en entrar, primero en salir" (LIFO).
La acción de agregar datos al stack se conoce como push, mientras que la de quitar datos se denomina pop. Todos los datos almacenados en el stack deben tener un tamaño conocido y fijo.
En contraste, los datos con un tamaño desconocido en tiempo de compilación o que pueden cambiar de tamaño deben almacenarse en el heap en lugar del stack.
El heap, por su parte, presenta una organización menos estructurada. Al colocar datos en el heap, solicita una cantidad específica de espacio. El administrador de memoria encuentra un espacio vacío lo suficientemente grande en el heap, lo marca como utilizado y devuelve un puntero, que es la dirección de esa ubicación. A este proceso se le denomina asignación en el heap y, a veces, se abrevia como "asignar". Dado que el puntero al heap tiene un tamaño conocido y fijo, puede almacenar dicho puntero en el stack. Sin embargo, cuando requiera acceder a los datos reales, debes seguir el puntero para recuperarlos.
Agregar datos al stack es más rápido que asignar en el heap debido a que el asignador nunca tiene que buscar un lugar para almacenar nuevos datos, ya que siempre se encuentran en la parte superior del stack. En contraste, asignar espacio en el heap requiere un mayor esfuerzo, ya que el asignador debe buscar un espacio lo suficientemente grande para almacenar los datos y llevar realizar tareas de contabilidad para futuras asignaciones.
Acceder a los datos en el heap es más lento que acceder a los datos en el stack porque se debe seguir un puntero para llegar allí. Los procesadores modernos son más rápidos si se desplazan menos en la memoria.
Cuando el código invoca una función, los valores pasados a la función y las variables locales de la función se empujan al stack. Cuando la función termina, esos valores se desapilan del stack.
Qué es el Ownership en Rust?
En Rust, el Ownership o la propiedad se define como un conjunto de reglas que rigen la administración de memoria en un programa. Recordemos, todos los programas deben gestionar el uso de memoria en una computadora durante su ejecución. Mientras que algunos lenguajes de programación emplean la recolección de basura (Garbage Collector) para liberar regularmente la memoria no utilizada durante la ejecución del programa, en otros lenguajes el programador debe asignar y liberar explícitamente la memoria. Rust adopta un enfoque distinto: la memoria se administra mediante un sistema de propiedad respaldado por un conjunto de reglas verificadas por el compilador*.* Si se viola alguna de estas reglas, el programa no se compilará.
Nota: Las características del sistema de propiedad no afectarán el rendimiento del programa durante su ejecución. Rust y las reglas del sistema de propiedad, facilitan desarrollar código que de forma natural sea seguro y eficiente.
El Ownership o la propiedad constituye la característica más distintiva de Rust y conlleva implicaciones profundas para el resto del lenguaje. Posibilita que Rust brinde garantías de seguridad de memoria sin requerir un recolector de basura.
En Rust, reglas de propiedad son:
Cada valor en Rust tiene un propietario.
Solo puede haber un propietario a la vez.
Cuando el propietario queda fuera de alcance, el valor será eliminado.
Recordemos que el ámbito de una variable es el rango dentro de un programa en el que un elemento es válido.
fn main() {
let cadena = "Hola Rust!";
println!("{cadena}");
}
La variable cadena es un literal de tipo str. La variable es válida desde que se declara hasta el final del ámbito actual, en este caso el fin de la función main. Permanece válido hasta que sale de ámbito.
En Rust, la relación entre los ámbitos y cuándo las variables son válidas es similar a la de otros lenguajes de programación.
Para poder comprender las reglas de propiedad utilizaremos los String, dado que es un tipo de datos más complejo que los tipos básicos. Con los String, podemos estudiar los datos que se almacenan en el heap y entender cómo Rust sabe cuándo limpiar dichos datos.
Los tipos básicos tienen un tamaño conocido, pueden ser almacenados en el stack y eliminados de ahí cuando su ámbito finaliza, además pueden ser copiados rápidamente y de manera trivial para crear una nueva instancia independiente en caso de que otra parte del código necesite utilizar el mismo valor en un ámbito diferente.
De String solo nos enfocaremos en su relacionan con la propiedad. Estos aspectos también se aplican a otros tipos de datos complejos.El código presentado anteriormente crea un literal de tipo cadena. Los literales de cadena son convenientes, pero no son adecuados para todas las situaciones, dado que son inmutables. Puede crear un String a partir de un literal de cadena utilizando la función from, así:
fn main() {
let cadena = String::from("Hola Rust!");
println!("{cadena}");
}
Este tipo de cadena String y esta variable en el contexto de nuestro ejemplo, puede ser mutable, si es el caso:
fn main() {
let mut cadena = String::from("Hola");
cadena.push_str(", Rust!");
println!("{cadena}");
}
En Rust, tanto str como String son tipos de datos que se utilizan para representar texto. Sin embargo, hay diferencias importantes entre ellos:
str (cadena de texto estática): Es un tipo de dato primitivo y se conoce como una "cadena de texto estática o litereal". Representa una secuencia inmutable de caracteres almacenados en la memoria estática. Estas cadenas están codificadas en UTF-8 y su tamaño no es conocido en tiempo de compilación. Para acceder a los datos de una cadena str, se utiliza una referencia &str.
String (cadena de texto dinámica): Es un tipo de dato que representa una "cadena de texto dinámica". A diferencia de str, String es una estructura de datos que permite almacenar y manipular cadenas de texto de manera dinámica. Puede agregar, eliminar, modificar y concatenar caracteres y subcadenas en un String. El tamaño de un String puede crecer o disminuir durante la ejecución del programa. Para acceder a los datos de un String, también se utiliza una referencia &String.
En resumen, str se refiere a una cadena de texto inmutable y estática, mientras que String se refiere a una cadena de texto mutable y dinámica.
Memoria y Asignación
Con String, es posible admitir un fragmento de texto mutable y escalable, esto implica que:
La memoria debe solicitarse al asignador de memoria en tiempo de ejecución.
Se requiere una forma de devolver esta memoria al asignador cuando el programa no utilice más el String.
La primera parte la hacemos nosotros: cuando invocamos a String::from, su implementación solicita la memoria que necesita. Esto es bastante común en los lenguajes de programación.
Sin embargo, la segunda parte es diferente. En lenguajes con un recolector de basura, este realiza un seguimiento y limpia la memoria que ya no se está utilizando, y no necesitamos preocuparnos por ello. En la mayoría de los lenguajes sin un recolector, es nuestra responsabilidad identificar cuándo la memoria ya no se está utilizando y llamar a un código para liberarla explícitamente, al igual que hicimos para solicitarla. Hacer esto correctamente es un problema de programación difícil.
Si se olvida, desperdiciaremos memoria.
Si lo hace demasiado pronto, tendremos una variable no válida.
Si lo hace dos veces, también es un error.
En Rust, la memoria se devuelve automáticamente una vez que la variable que la posee queda fuera de alcance.
Devolvemos la memoria que necesita un String al asignador, cuando cadena (nuestra variable) queda fuera de alcance. Cuando una variable queda fuera de alcance, Rust llama automaticamente a la función drop, y para este contexto devuelve la memoria de nuestro String. Rust llama automáticamente a drop al llegar al corchete de cierre.
En el siguiente ejemplo, múltiples variables pueden interactuar con los mismos datos de diferentes maneras en Rust. Ahora tenemos dos variables, numero1 y numero2, y ambas son iguales a 5, porque los enteros, son valores simples con un tamaño conocido y fijo, y estos dos valores se empujan al stack.
fn main() {
let entero1 = 5;
let entero2 = entero1;
println!("{entero1}");
println!("{entero2}");
}
Ahora veamos la versión con String:
fn main() {
let cadena1 = String::from("Hola Rust!");
let cadena2 = cadena1;
println!("{cadena1}");
println!("{cadena2}");
}
Nota: Este código generar un error en tiempo de compilación. El error se explicará un poco más adelante, si desea compilar y ejecutar, comente la línea println!("{cadena1}");.
Este código parece muy similar, por lo que podríamos asumir que funciona de la misma manera: es decir, que la segunda línea haría una copia del valor en cadena1 y lo asignaría a cadena2. Pero realmente no es así.
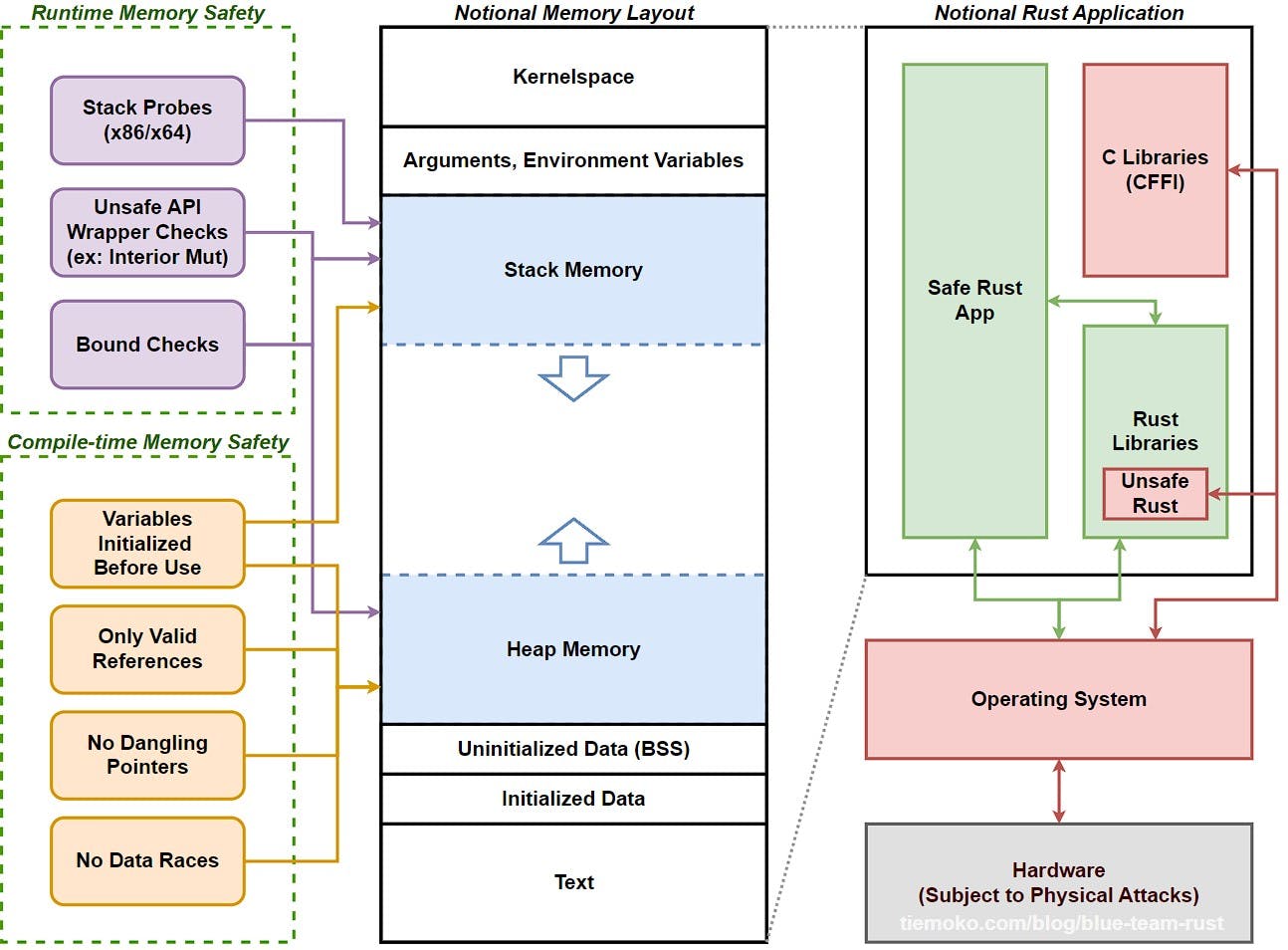
Un String se compone de tres partes: un puntero a la memoria que contiene el contenido de la cadena, una longitud y una capacidad. Este grupo de datos se almacena en el stack. El contenido, es decir, la cadena, se almacena en el heap.
La longitud representa la cantidad de memoria (en bytes), que actualmente están utilizando la cadena. La capacidad es la cantidad total de memoria (en bytes), que el String ha recibido del asignador de memoria. La diferencia entre la longitud y la capacidad es relevante, pero no en este contexto.
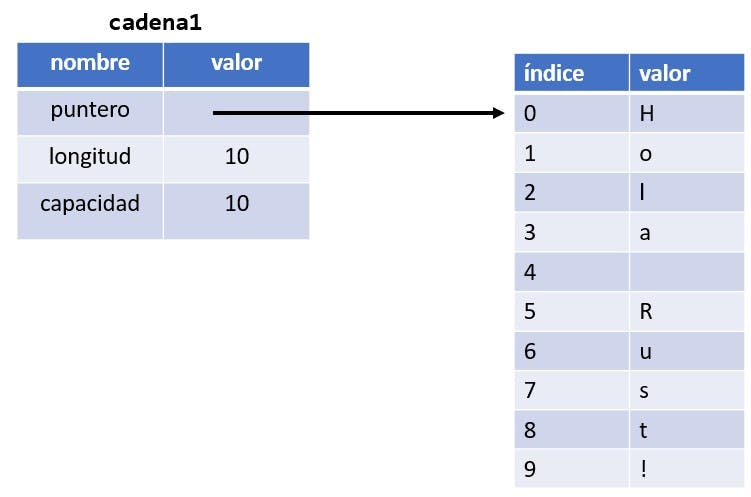
Cuando asignamos cadena1 a cadena2, los datos del String se copian, lo que significa que copiamos el puntero, la longitud y la capacidad que se encuentran en el stack. No copiamos los datos en el heap a los que apunta el puntero. En otras palabras, la representación de los datos en memoria se ve como:
Como podemos observar en el gráfico anterior, solo se realiza una copia de la referencia y no una copia de los datos en el heap. Si Rust hiciera esto, la operación cadena2 = cadena1 podría ser muy costosa en cuanto al rendimiento en tiempo de ejecución si los datos en el heap fueran grandes.
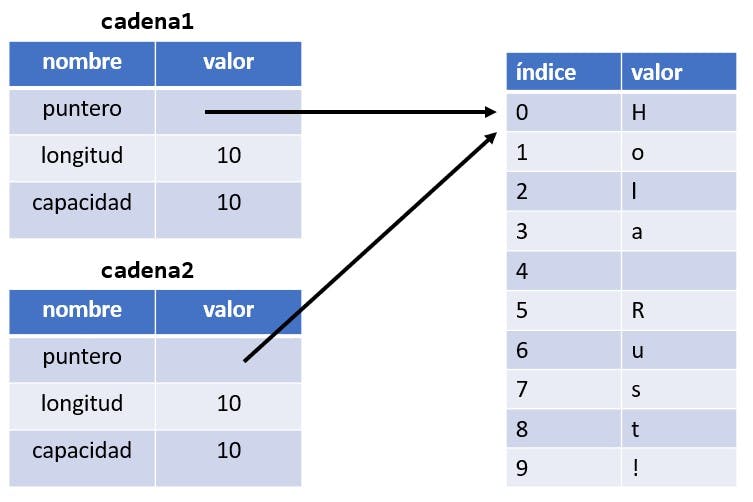
La gráfica presentada a continuación es que es cómo se vería la memoria si Rust copiara también los datos del heap, pero como mencionamos esto no es lo que ocurre.
Mencionamos que cuando una variable queda fuera de alcance, Rust llama automáticamente a la función drop y limpia la memoria del heap para esa variable. Sin embargo, cuando realizamos la operación cadena2 = cadena1 ambos punteros apuntan al mismo lugar. Esto es un problema: cuando cadena2 y cadena1 quedan fuera de alcance, ambos intentarán liberar la misma memoria. Esto se conoce como un error de doble liberación y es uno de los errores de seguridad de memoria. Liberar memoria dos veces puede provocar corrupción de memoria, y esto puede generar problemas de seguridad.
Para garantizar la seguridad de memoria, después de la línea let cadena2 = cadena1;, Rust considera que cadena1 ya no es válida. Por lo tanto, Rust no necesita liberar nada cuando cadena1 queda fuera de alcance. Observa lo que sucede cuando intenta utilizar cadena1 después de crear cadena2; no funcionará. Por esta razón el código anterior generaba un error en tiempo de compilación.
fn main() {
let cadena1 = String::from("Hola Rust!");
let cadena2 = cadena1;
println!("{cadena1}");
println!("{cadena2}");
}
Obtiene un error como este porque Rust impide utilizar la referencia invalidada.
Si está familiarizado con los términos copia superficial y copia profunda utilizados en otros lenguajes, es posible que el concepto de copiar en Rust el puntero, la longitud y la capacidad sin copiar los datos aparente ser copia superficial. Sin embargo, debido a que Rust invalida la primera variable, en lugar de ser considerada una copia superficial, se conoce como un movimiento (move). En este ejemplo, podríamos decir que cadena1 fue movida a cadena2. Por lo tanto, lo que realmente ocurre se muestra en la gráfica:
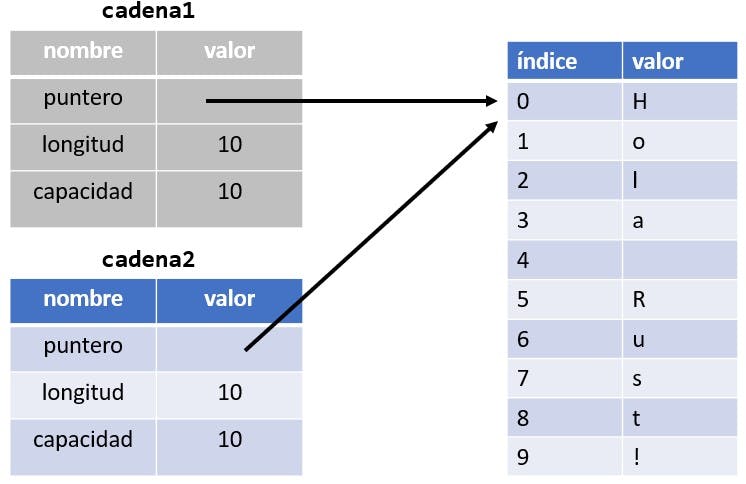
Con solo cadena2 siendo válido, cuando la variable sale de alcance, Rust liberará la memoria del único elemento válido. Rust nunca creará automáticamente copias profundas de los datos. Por lo tanto, se puede asumir que cualquier copia automática es económica en términos de rendimiento en tiempo de ejecución.
Para finalizar, si desea realizar una copia profunda de los datos almacenados en el heap de la cadena (String), no solo los datos de la stack, puede utilizar el método clone. Ejemplo del método clone:
fn main() {
let cadena1 = String::from("Hola Rust!");
let cadena2 = cadena1.clone();
println!("{cadena1}");
println!("{cadena2}");
}
Él clone no es necesario para tipos básicos, como los enteros, la razón es que estos tipos tienen un tamaño conocido en tiempo de compilación, se almacenan por completo en el stack, por lo que las copias de los valores reales se ejecutan rápidamente. En otras palabras, no hay diferencia entre la copia profunda y la copia superficial, por lo que llamar a clone no haría nada diferente a la copia habitual.
Lista de tipos que no requieren clone:
Todos los tipos enteros, como u32.
El tipo boolean.
Todos los tipos de punto flotante, como f64.
El tipo de carácter, char.
Las tuplas, si solo contienen tipos listados previamente. Por ejemplo, (i32, i32), pero NO (i32, String).
Referencias
Este post es un resumen en español del capítulo 4 del libro "The Rust Programming Language. 2nd Edition by Steve Klabnik and Carol Nichols, with contributions from the Rust Community. 2023"